Данные под маской

Для защиты данных применяется множество решений. Компании защищают инфраструктуры и сети передачи от несанкционированного проникновения, шифруют данные, делают резервные копии, борются с разными видами мошенничества. Но угрозу несут не только действия злоумышленников. Сделать массив информации непригодным для использования могут и «шаловливые ручки» пользователей, и даже некорректная работа информационных систем. И один из видов защиты от таких проблем – маскирование данных.
Маскирование данных (его еще называют обфускацией) – один из способов защиты конфиденциальной информации от несанкционированного использования. При маскировании данные заменяются либо произвольными символами, либо (что чаще) – фиктивными данными. Массив информации после маскировки выглядит вполне реалистично.
Наиболее примитивный способ маскирования можно наблюдать в интернет-сервисах бесплатных объявлений, когда система скрывает номер телефона продавца или покупателя. Это делается для того, чтобы исключить сбор такой информации ботами. Для того, чтобы данные демаскировать, в большинстве случаев нужно нажать на кнопку «показать телефон». Но даже такого маскирования оказывается достаточно, чтобы хоть как-то оградить подателей объявлений от волн спама (хотя, конечно, о серьезной защите в этом случае речи не идет).
Еще один пример – представление номеров банковских карт в мобильных приложениях и интернет-банках. Чаще всего цифры в номере скрывают звездочками, оставляя только последние четыре, для того, чтобы номер карты не стал доступен злоумышленнику, случайно завладевшему устройством владельца карты.
Чем отличается маскирование от шифрования
Кажется, что маскирование и шифрование данных – одно и то же. Более того, даже некоторые специалисты считают шифрование разновидностью маскирования. Тем не менее, это – совсем разные процессы.
Шифрование подразумевает доступ к данным при вводе ключа. Если у пользователя он есть – он сможет прочитать все. Но ключ, как известно, можно добыть при помощи четырехсот сравнительно несложных способов, начиная с перебора при помощи специальной программы, и заканчивая разогретым утюгом. Маскирование же используется для того, чтобы посторонний ни при каких условиях доступа к информации не получил.
Шифрование подразумевает обратимость: если у пользователя есть ключ, то он может не только просмотреть данные, но и отредактировать их. Маскирование при водит к тому, что данные изменить (фрагментировать их, редактировать, скрыть или удалить) становится невозможным.
Маскирование не подразумевает шифрования. Данные просто прячутся от всех, кому они не предназначены, а доступ к ним определяется политиками безопасности. Есть у пользователя полномочия? Значит, он получит доступ к информации. Нет? Следовательно, он тоже увидит данные, но только – фейковые. И, если он получил доступ к массиву случайно (или неправомерно), то может даже и не понять, что имеет дело не с достоверными сведениями, а фейком. Ведь маскированные данные выглядят точно так же, как достоверные.
Когда стоит применять маскирование
Шифрование чаще всего применяется, когда необходимо защитить файл или массив данных при их перемещении – от одного компьютера к другому или в рамках сети. В большинстве случаев речь идет о том, чтобы предотвратить доступ к ним кого-то помимо отправителя или получателя (или нескольких получателей). Или – когда данные могут оказаться в средах с неавторизованным доступом.
Назначение маскирования гораздо шире. Оно применяется там, где информация, которую необходимо защитить, так или иначе будет доступна многим пользователям. К примеру, маскирование стоит использовать, если доступ к массиву информации открывается аутсорсинговым компаниям, удаленным сотрудникам, подрядчикам. К слову, особенно актуально выглядит маскирование в сопоставлении с удаленным режимом работы.
Не обойтись без маскирования и в бимодальных или гиперконвергентных средах, когда информационные системы получают доступ к данным, хранящимся в разных местах: частных облаках или публичных, массивах Big Data или социальных сетях.
Маскирование активно применяют и при разработке корпоративных информационных систем и бизнес-приложений. В таких случаях важно протестировать сценарии или приложения в специальных средах, которые тождественны тем, в которых будет работать приложение после запуска. Чтобы не «испортить» данные, при подготовке релизов и их проверке используют массивы замаскированных данных – ведь реальное содержание в данном случае значения не имеет.
Каким бывает маскирование
Простой способ маскировки данных – статический. Он прост: создается копия базы данных, элементы которой подменяются фейками. Так чаще всего и поступают при использовании маскирования в разработке: для решения реальных задач такие данные уже не используются, их маскирование необратимо, но для того, чтобы использоваться в разработке, они подходят прекрасно.
Второй способ сложнее. Его используют в тех случаях, когда массив данных будет использоваться «по прямому назначению». Это – динамическое маскирование. Оно может применяться для массивов данных, к которым открыт доступ для подрядчиков и аутсорсеров. Его, к примеру, выбирают при проведении банковских транзакций. Иными словами, если речь идет о данных, которые используются сложными информационными системами и решениями с бимодальной архитектурой, то используется именно динамическое маскирование.
Вот пример реализации динамического маскирования. На нем хорошо видно, что разные категории пользователей видят разное представление данных – в зависимости от тех прав доступа, которыми они наделены в системе.
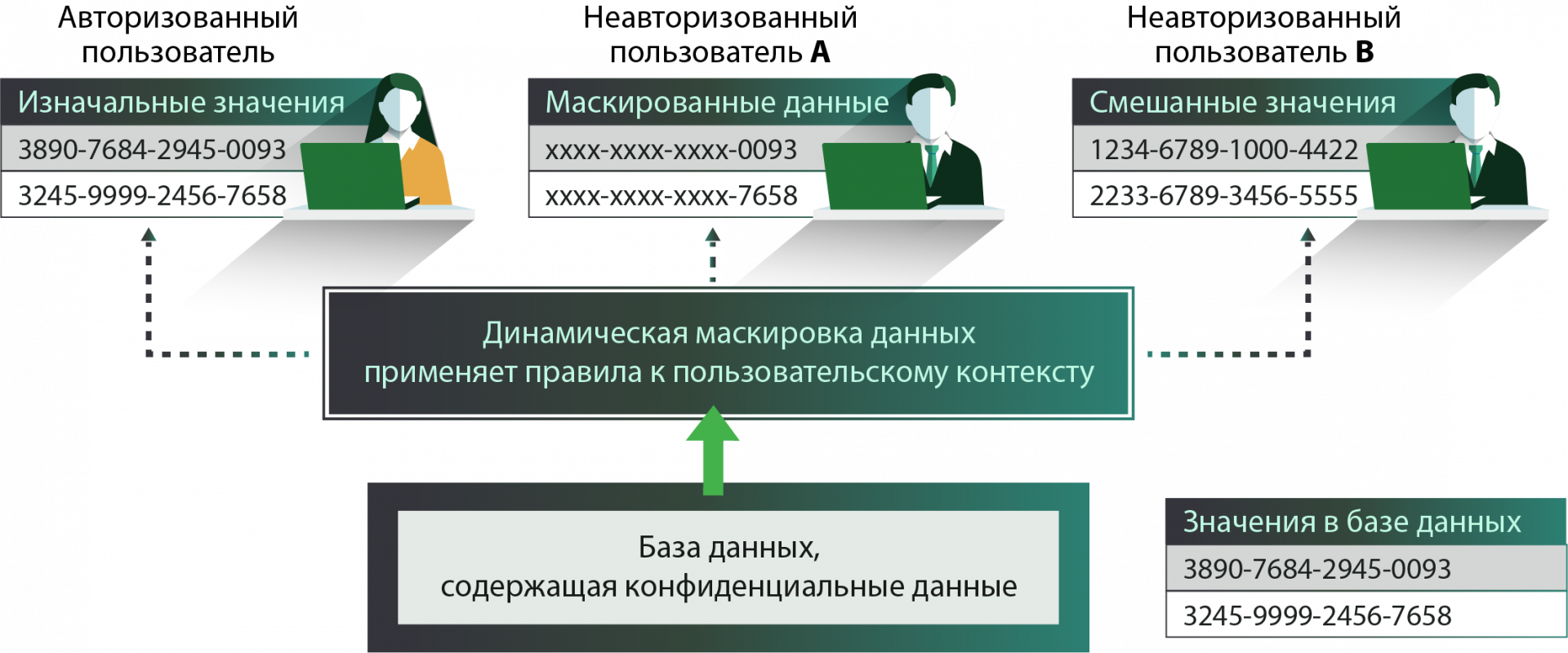
Источник - Tadvisor.ru
IBM InfoSphere Optim Data Privacy
Решения для маскирования данных предлагают многие поставщики. Но мы остановимся на одном из них – IBM InfoSphere Optim Data Privacy. Выбор обуславливается просто: IBM рассматривает маскирование не как операцию с данными, а как один из элементов управления ими. Такой подход наиболее полезен для компаний, которые нуждаются в том, чтобы обеспечить конфиденциальность данных, с которыми приходится работать при решении реальных бизнес-задач.
InfoSphere Optim – элемент целой стратегии IBM, Integrated Data Management. Она одновременно и определяет подход к развитию информационных систем заказчиков (вспомним про маскирование данных для нужд разработки бизнес-приложений), и позволяет формировать бимодальные архитектуры, которые «питаются» данными из множества источников и обеспечивают возможность использования информации из множества хранилищ.
Соответственно, и семейство решений IBM InfoSphere Optim нацелено на все циклы работы с данными: их извлечение из различных источников, их хранение и архивирование (в том числе в составе приложений), ускорение цикла разработки, и, в том числе – обеспечение сохранности.
Главное достоинство IBM InfoSphere Optim Data Privacy – готовность решения работать со множеством информационных сред. Оно поддерживает и MS SQL, и SAP, и массу других платформ, что делает его практически универсальным.